The Quiet Death of the Public API: Why Scraping Is the New Integration


The Scraper
Proxy Fundamentals
There's a pattern playing out across the web that doesn't get enough attention: public APIs are dying. Not dramatically, there's no API apocalypse, no industry-wide announcement. Just a steady accumulation of access restrictions, pricing changes, and API sunsets that, taken together, represent a fundamental shift in how data flows across the internet.
And the teams adapting fastest are the ones who've stopped waiting for API access and started building scrapers instead.
The Restriction Wave
It started with Twitter/X in 2023. The API that academics, developers, and research teams had built on for a decade went from free to prohibitively expensive overnight. A research pipeline that cost $0/month became $5,000/month or impossible, depending on the access tier.
Reddit followed. LinkedIn tightened. Instagram's API, already severely restricted, became essentially inaccessible for third-party applications. Google deprecated and restricted various data APIs. The pattern: platforms that grew on the promise of open ecosystems are now treating their data as a core asset to be monetized or withheld.
The reasoning isn't mysterious. Platform data powers AI training. Every company that licensed API access cheaply is now watching that data fuel competitive AI products. The tap is being turned off.
But the data is still there. Publicly visible. Right there in the browser.
What Actually Changed
The API restriction wave didn't make data inaccessible. It made it inaccessible through the official channel. The data rendered in a browser is the same data that used to come through an API, in many cases with more context, not less.
When Reddit killed its free API tier, the posts, comments, votes, and user histories didn't disappear. They're still rendered on reddit.com for anyone with a browser. The API restriction removed a clean programmatic interface to the data. It didn't remove the data.
This distinction is important because it reframes the engineering problem. Before API restrictions, the question was "how do I integrate with this API?" The question is now "how do I reliably extract this data from the interface the platform is willing to serve?" That's a scraping problem.
The Integration Use Cases That Migrated
Several categories of integration have quietly shifted from API-based to scraping-based:
Competitive intelligence. Monitoring competitors' pricing, product changes, and content strategies. Previously: some vendors had APIs; most didn't. Now: the ones who had APIs have restricted them, and scraping is universal.
Research and analytics. Academic social media research, market research, financial data aggregation. The Twitter/X API shutdown didn't stop social media researc, it moved the researchers to different tools and workflows, most of them scraping-based.
Aggregation products. Price comparison engines, travel aggregators, real estate platforms. These have always been scrapers; some supplemented with API access. The API access is being stripped away; the scraping continues.
AI training data. The fastest-growing use case. The major data providers are restricting access specifically because of AI training demand. Scrapers are the workaround.
Monitoring and alerting. Product availability alerts, price drop notifications, content change monitoring. For most of these use cases, there was never an API, scraping was always the method.
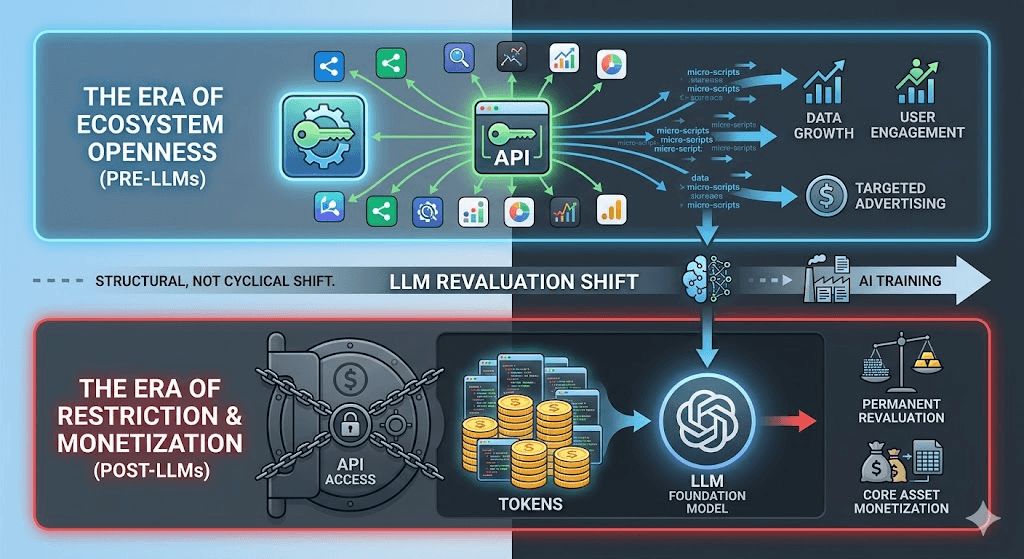
Why APIs Won't Come Back
The API restriction trend is structural, not cyclical. The economics have permanently shifted.
Before large language models, platform data was valuable for targeted advertising and third-party app ecosystems. APIs enabled ecosystems that drove engagement and data growth. The calculus favored openness.
After large language models, platform data is training fuel. The marginal value of each token scraped from a platform has increased dramatically. The calculus now favors restriction and monetization.
Additionally, platforms have gotten better at understanding how their data is used. When Reddit or Twitter could see that their API was being used to train foundation models worth billions of dollars, the justification for cheap access disappeared. They're not wrong that their data is more valuable than their old API pricing implied.
This isn't a temporary mispricing that will correct itself. It's a permanent revaluation.
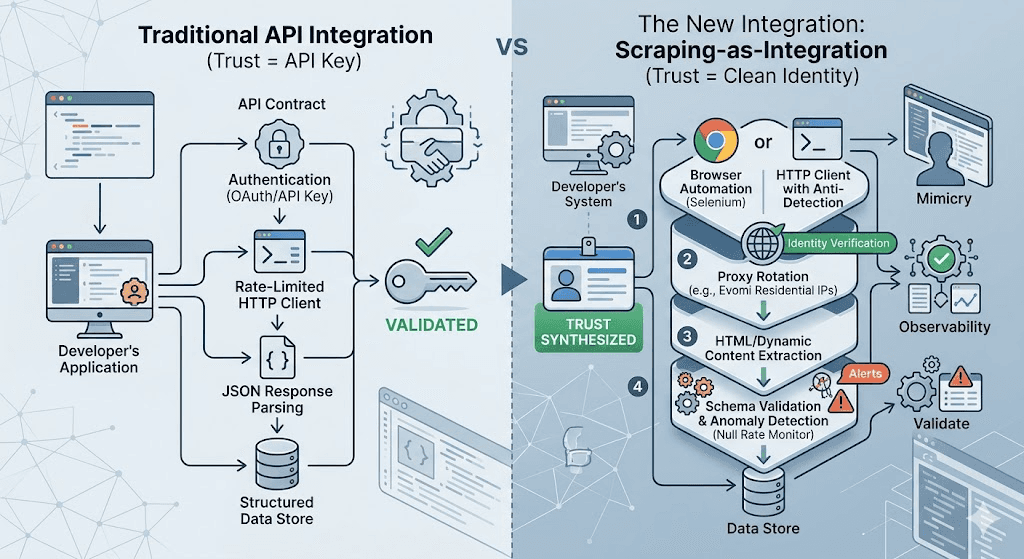
The New Stack for API-Less Integration
When you're building an integration against a target that used to have an API and doesn't anymore, or never had one, the architecture changes.
The old API integration stack:
Authentication (OAuth, API key)
Rate-limited HTTP client
JSON response parsing
Data store
The scraping integration stack:
Browser automation or HTTP client with anti-detection
Proxy rotation for IP diversity
HTML or dynamic content extraction
Schema validation (because you're now trusting your parser, not an API contract)
Freshness monitoring (because there's no webhook to tell you when things change)
Data store
The scraping stack is more complex. It has more moving parts, more failure modes, and no SLA from the data source. That's the honest trade-off.
But it works. And for most of the use cases that used to depend on now-restricted APIs, it's the only option that still works.
The Reliability Question
The objection to scraping as integration is usually reliability: APIs have versioned contracts; scrapers break when sites change. This is fair, but it's not as asymmetric as it sounds.
APIs break too. Reddit's API pricing changed without adequate notice. Twitter's API changed overnight. The "stable contract" of an API is contingent on the platform honoring it, and they don't always.
Well-instrumented scrapers with schema validation and anomaly detection (see: observability-driven scraping) catch breaks quickly. The mean time to detection for a schema change is hours if you're monitoring null rates by field. The mean time to detection for an API pricing change is often zero, you find out the same day and have to rebuild anyway.
The practical reliability gap between scraping and APIs is smaller than it appears, especially for platforms that have demonstrated willingness to change their API terms unilaterally.
Where Evomi Fits in API-Less Integration
The access problem that scraping solves, but that APIs never had, is that you need to look like a legitimate user, not an automated client. APIs authenticate you as a developer. Scrapers have to authenticate you as a human.
This is where proxy quality directly determines integration reliability. A clean residential IP that matches the geographic profile of your data need is the foundation of scraping-as-integration. Without it, you're fighting the anti-bot layer constantly instead of building on top of it.
Evomi's residential proxies are purpose-built for this: high-quality, ethically sourced IPs across 195+ countries that maintain the low fraud scores needed for trusted access. For teams migrating from API-based to scraping-based integrations, the proxy layer is the first dependency to get right.
The platforms aren't bringing the APIs back. Build accordingly.

Author
The Scraper
Engineer and Webscraping Specialist
About Author
The Scraper is a software engineer and web scraping specialist, focused on building production-grade data extraction systems. His work centers on large-scale crawling, anti-bot evasion, proxy infrastructure, and browser automation. He writes about real-world scraping failures, silent data corruption, and systems that operate at scale.


