Your Scraper Isn’t Blocked - It’s Just Lying to You


The Scraper
Proxy Fundamentals
In the world of web automation, Hard Blocks (403s, CAPTCHAs, and Cloudflare walls) are actually a blessing. They are loud. They break the build. They force you to fix the problem immediately.
The real killers are Soft Blocks.
The Anatomy of a Silent Failure
A soft block is a sophisticated defense mechanism where a website serves a "valid" response that contains "invalid" data. To your monitoring tools, everything looks perfect:
The selectors still return nodes.
The HTTP status is
200 OK.The crawler didn't crash.
But inside the HTML, the prices are gone, the search results are halved, or the inventory is set to a placeholder value. If your monitoring only tracks status codes and proxy success rates, you are flying blind. This is where "Transport Success" masks "Data Failure."

Why the Modern Web is a Moving Target
We no longer scrape static documents; we scrape dynamic applications. This introduces four critical variables that cause "Data Drift":
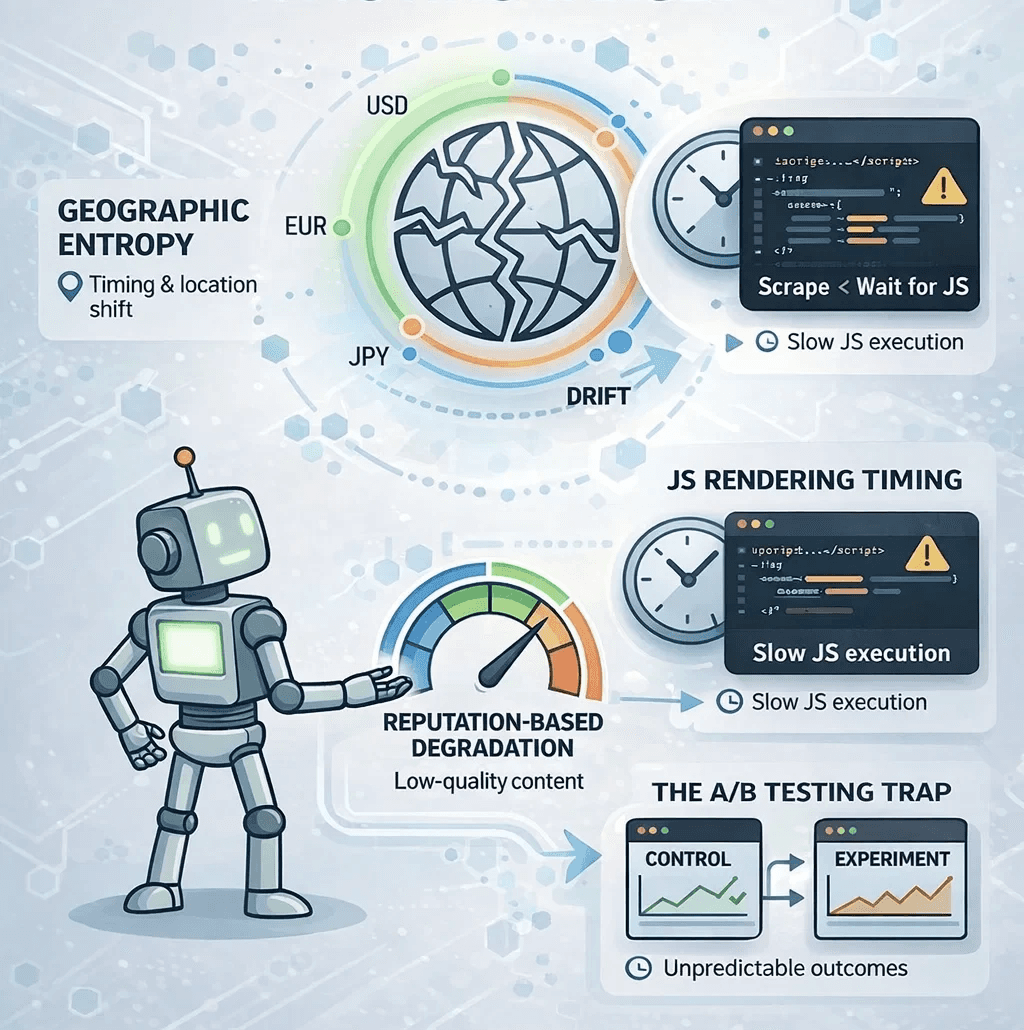
1. Geographic Entropy
Many sites use Geo-IP to determine availability. If your proxy pool rotates through different countries without "sticky" sessions, your dataset becomes a "Frankenstein" of global prices. A hotel rate in London requested from a Tokyo IP isn't just different, it’s irrelevant to a UK-based traveler.
2. The Execution Gap
Modern frameworks (React, Vue, Next.js) often serve an empty shell initially. If your scraper captures the DOM before the client-side JavaScript hooks have fired, you’ll extract empty divs. The page "loaded," but the data hadn't "arrived."
3. Reputation-Based Degradation
High-tier anti-bot systems have moved beyond binary "Allow/Block" logic. Instead, they use Rate-Limiting through Degradation. If your IP reputation is low, they might serve you cached data from three hours ago or hide high-value fields like "Stock Count" while keeping the rest of the page intact.
4. The A/B Test Trap
Websites constantly run experiments. Your scraper might be stuck in a "Control Group" that sees a different UI layout or pricing tier than 95% of real users. Without cross-validation, your analytical model will be built on an outlier.
The Strategic Blueprint: Building a Validation Layer
Elite scraping teams have shifted their focus from extraction to verification. They’ve realized that collecting terabytes of garbage data is worse than collecting nothing at all.
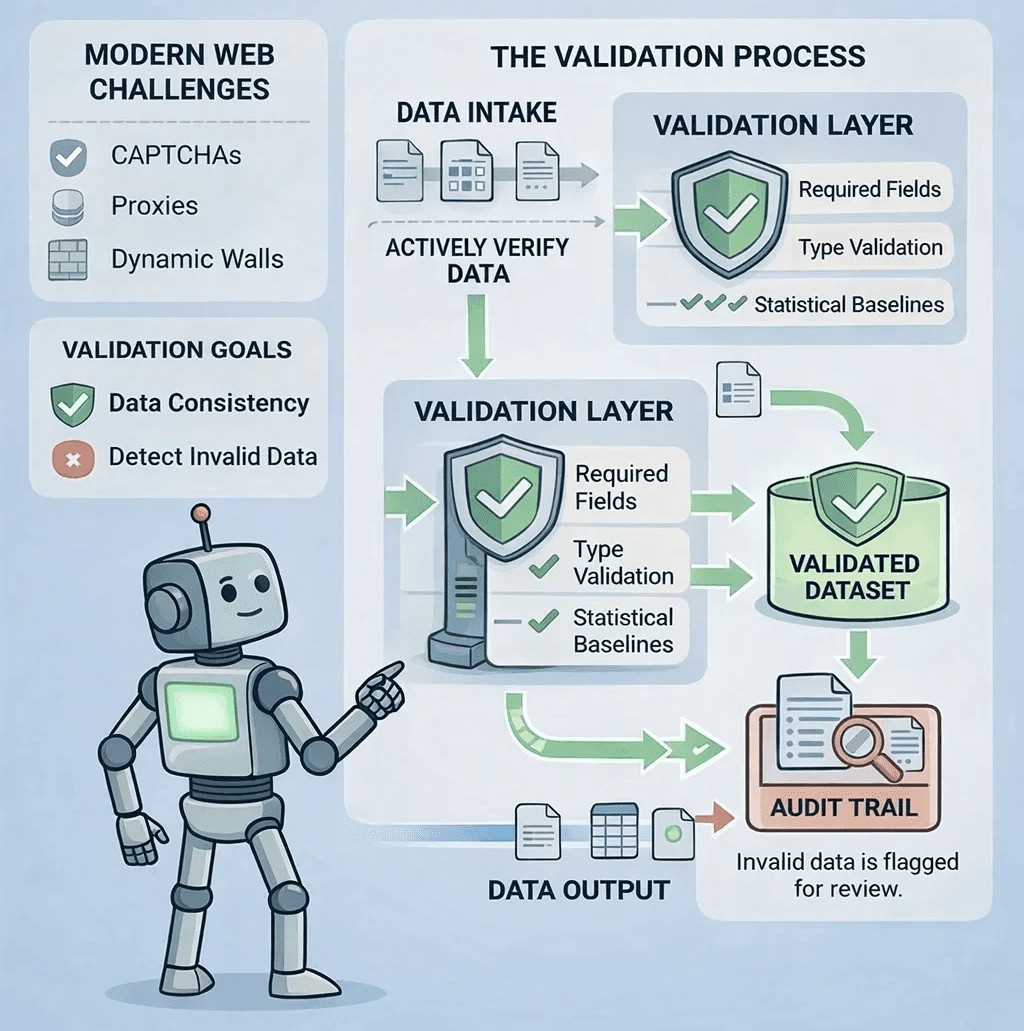
To build a "Trust-First" pipeline, you must implement three layers of defense:
Layer 1: Content Completeness (The Micro View)
Stop trusting the HTTP code. Every request should pass a "Schema Guard."
Required Fields: If a product page is missing a Price or a SKU, it’s a failure.
Type Validation: If a "Price" field returns a string like "Login for Price," your scraper hasn't succeeded—it's been diverted.
Layer 2: Statistical Baselines (The Macro View)
Monitor the "shape" of your data in real-time.
Null-Rate Spikes: If your average null rate for "Delivery Date" jumps from 2% to 15%, your selectors are likely broken or the site has updated its layout.
Volume Thresholds: If a category page usually yields 40 items and suddenly yields 4, you are likely facing a soft block.
Layer 3: Environment Pinning
Ensure your network identity is consistent. Use Sticky Proxy Sessions to keep your IP, User-Agent, and Cookies locked to a specific geographic region for the duration of a crawl. This prevents the "Mixed Reality" problem where data points from different regions are incorrectly aggregated.
Conclusion: Data is the Only Metric
The goal of web scraping isn’t to retrieve pages; it’s to produce reliable datasets. Infrastructure is only successful when the data it produces can be audited and trusted. In the end, the most dangerous scraping failures aren't the ones that crash your script—they’re the ones that quietly keep running while your database fills with fiction.
If you aren't monitoring your data quality, you aren't scraping; you're just guessing.
In the world of web automation, Hard Blocks (403s, CAPTCHAs, and Cloudflare walls) are actually a blessing. They are loud. They break the build. They force you to fix the problem immediately.
The real killers are Soft Blocks.
The Anatomy of a Silent Failure
A soft block is a sophisticated defense mechanism where a website serves a "valid" response that contains "invalid" data. To your monitoring tools, everything looks perfect:
The selectors still return nodes.
The HTTP status is
200 OK.The crawler didn't crash.
But inside the HTML, the prices are gone, the search results are halved, or the inventory is set to a placeholder value. If your monitoring only tracks status codes and proxy success rates, you are flying blind. This is where "Transport Success" masks "Data Failure."
Why the Modern Web is a Moving Target
We no longer scrape static documents; we scrape dynamic applications. This introduces four critical variables that cause "Data Drift":
1. Geographic Entropy
Many sites use Geo-IP to determine availability. If your proxy pool rotates through different countries without "sticky" sessions, your dataset becomes a "Frankenstein" of global prices. A hotel rate in London requested from a Tokyo IP isn't just different, it’s irrelevant to a UK-based traveler.
2. The Execution Gap
Modern frameworks (React, Vue, Next.js) often serve an empty shell initially. If your scraper captures the DOM before the client-side JavaScript hooks have fired, you’ll extract empty divs. The page "loaded," but the data hadn't "arrived."
3. Reputation-Based Degradation
High-tier anti-bot systems have moved beyond binary "Allow/Block" logic. Instead, they use Rate-Limiting through Degradation. If your IP reputation is low, they might serve you cached data from three hours ago or hide high-value fields like "Stock Count" while keeping the rest of the page intact.
4. The A/B Test Trap
Websites constantly run experiments. Your scraper might be stuck in a "Control Group" that sees a different UI layout or pricing tier than 95% of real users. Without cross-validation, your analytical model will be built on an outlier.
The Strategic Blueprint: Building a Validation Layer
Elite scraping teams have shifted their focus from extraction to verification. They’ve realized that collecting terabytes of garbage data is worse than collecting nothing at all.
To build a "Trust-First" pipeline, you must implement three layers of defense:
Layer 1: Content Completeness (The Micro View)
Stop trusting the HTTP code. Every request should pass a "Schema Guard."
Required Fields: If a product page is missing a Price or a SKU, it’s a failure.
Type Validation: If a "Price" field returns a string like "Login for Price," your scraper hasn't succeeded—it's been diverted.
Layer 2: Statistical Baselines (The Macro View)
Monitor the "shape" of your data in real-time.
Null-Rate Spikes: If your average null rate for "Delivery Date" jumps from 2% to 15%, your selectors are likely broken or the site has updated its layout.
Volume Thresholds: If a category page usually yields 40 items and suddenly yields 4, you are likely facing a soft block.
Layer 3: Environment Pinning
Ensure your network identity is consistent. Use Sticky Proxy Sessions to keep your IP, User-Agent, and Cookies locked to a specific geographic region for the duration of a crawl. This prevents the "Mixed Reality" problem where data points from different regions are incorrectly aggregated.
Conclusion: Data is the Only Metric
The goal of web scraping isn’t to retrieve pages; it’s to produce reliable datasets. Infrastructure is only successful when the data it produces can be audited and trusted. In the end, the most dangerous scraping failures aren't the ones that crash your script—they’re the ones that quietly keep running while your database fills with fiction.
If you aren't monitoring your data quality, you aren't scraping; you're just guessing.

Author
The Scraper
Engineer and Webscraping Specialist
About Author
The Scraper is a software engineer and web scraping specialist, focused on building production-grade data extraction systems. His work centers on large-scale crawling, anti-bot evasion, proxy infrastructure, and browser automation. He writes about real-world scraping failures, silent data corruption, and systems that operate at scale.


