Beyond the Bug: Why Scrapers Die Quietly in Production


The Scraper
Scraping Techniques
If you’ve ever built a scraper that worked like a charm on your local machine only to watch it crumble in the cloud, you know the feeling.
Everything looks green on the dashboard. The requests are resolving. The logs say 200 OK. But three weeks later, a stakeholder points out that the data is garbage. The prices are wrong, the products are missing, and your "successful" pipeline has been feeding the business hallucinations.
The truth? Your code probably isn't the problem. Most scraping systems don't fail because of a logic error; they fail because they can't handle the "silent rot" of the web environment.
1. The "200 OK" Lie
Modern scraping stacks are actually quite robust at handling HTML parsing and retries. Those are solved problems. The real bottleneck is environmental drift.
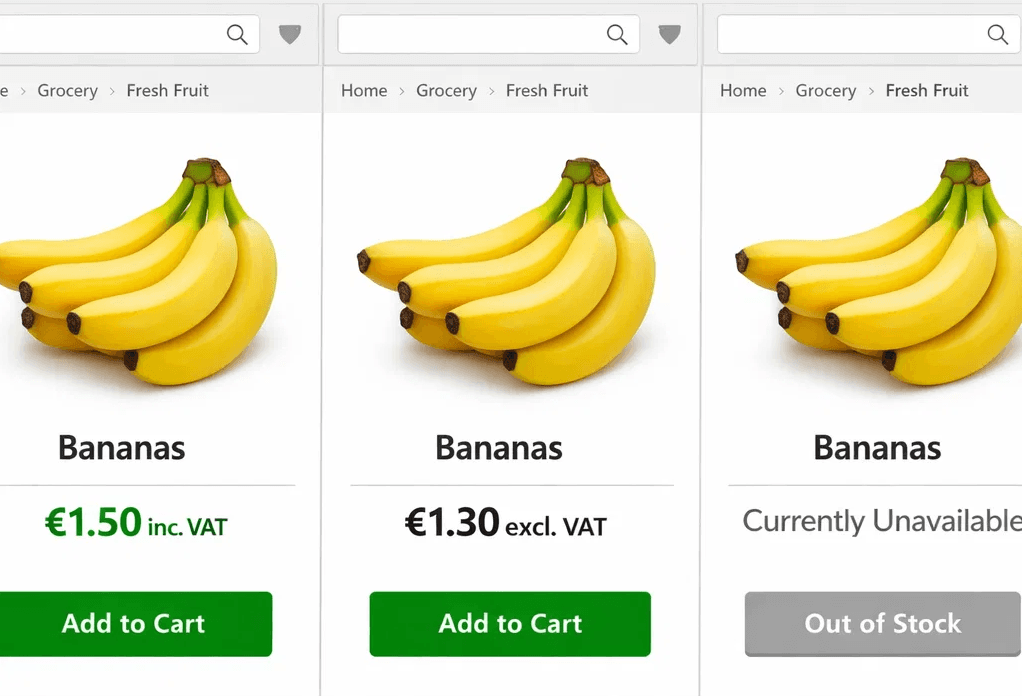
Imagine a price monitor running across Europe. The selectors are fine. The code hasn’t changed. But because of the proxy's IP reputation or geo-location:
Market A sees VAT-inclusive prices.
Market B gets a "soft" redirect to a landing page.
Market C sees a "Product Unavailable" notice that looks like a valid empty state.
The system didn't crash. It failed operationally while technically succeeding.
2. Silent Failure: The Invisible Budget Killer
A hard crash is a gift, it tells you exactly where to fix it. A soft failure is a nightmare.
Websites have become experts at serving "ghost" pages: valid HTML that contains CAPTCHAs, limited search results, or localized content intended to mislead automated agents. From your scraper's perspective, it got a response. From a business perspective, you’re making decisions based on corrupted data.
The Lesson: If you aren't validating the integrity of the content, you aren't really scraping; you're just downloading noise.
3. Quality Over Quantity (The Proxy Trap)
There is a persistent myth that a larger proxy pool equals better reliability. In reality, massive, low-quality pools are often "polluted."
Aggressive Rotation: Can actually trigger anomaly detection by making your session behavior look erratic.
IP Reputation: A small set of "clean," stable residential IPs is infinitely more valuable than 100,000 blacklisted data center IPs.
This is where infrastructure providers like Evomi shift the needle. By treating proxies as stateful assets rather than disposable commodities, they ensure geographic consistency and session continuity. It’s the difference between a bot that looks like a bot and a bot that looks like a loyal customer.
4. Retries are a Double-Edged Sword
We love a good retry logic, but in production, it often just masks structural decay.
If a scraper hits a wall and you increase retries from 3 to 10, your "success rate" might go up, but your data freshness plummets. You’re effectively brute-forcing your way into accepting stale or throttled data.
In production, you need to distinguish between a "hiccup" (transient network error) and a "block" (reputation-based rejection). Treating them the same is just delaying the inevitable collapse.
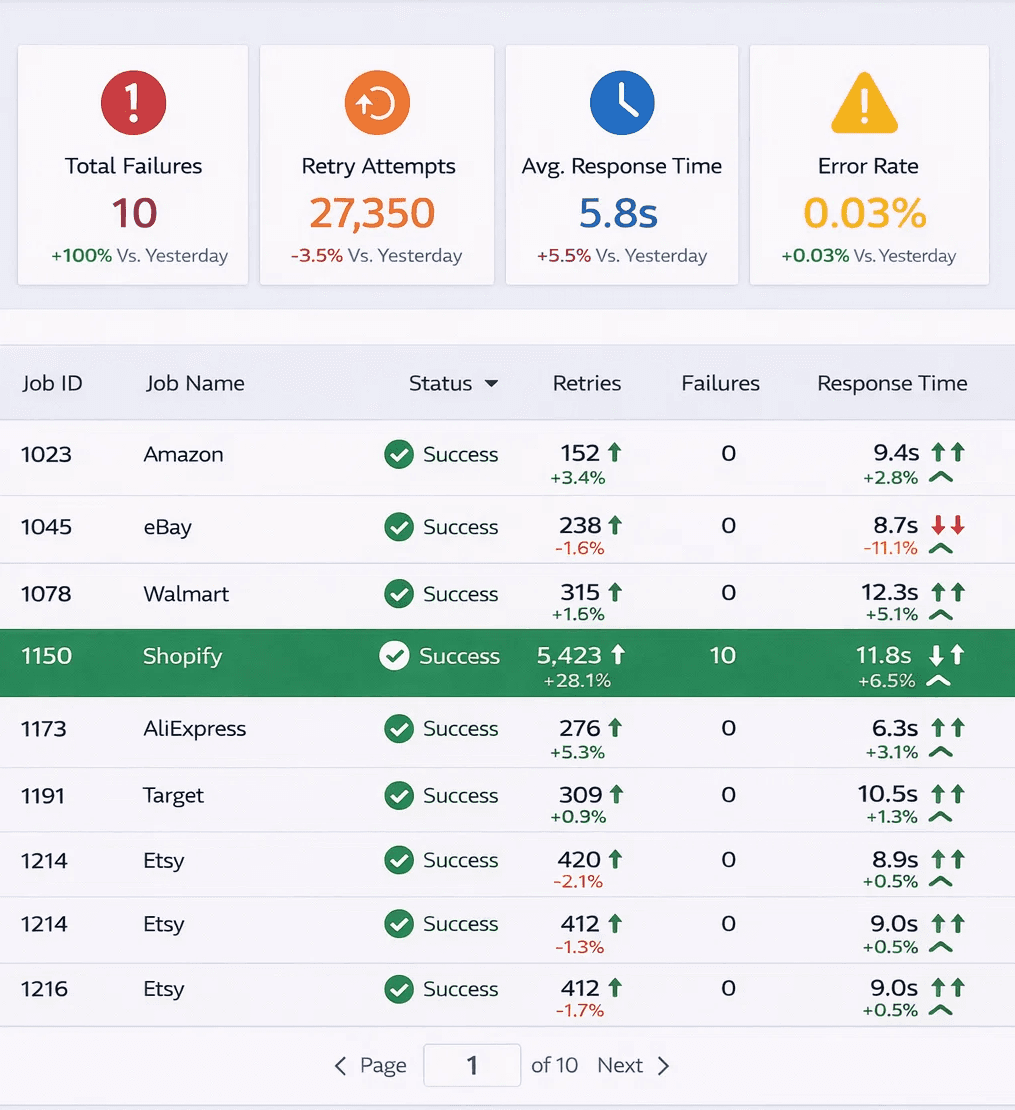
5. Observability: More Than Just Uptime
A production scraper needs to answer more than "Did it run?" It needs to answer:
Did the average response size drop by 20%?
Are failures clustering around a specific provider or region?
Has the "Price" field suddenly become null in 5% of records?
Without deep observability, proxy issues don't show up as alerts, they show up as bad quarterly reports.
The Bottom Line
At scale, web scraping is no longer a coding challenge, it’s an infrastructure challenge.
It’s about managing reputation, matching human-like behavior, and choosing a "reliability layer" that can handle the heat of a production workload. If your data is drifting, stop looking at your scripts and start looking at your proxies.
Stop optimizing for volume. Start optimizing for trust.
If you’ve ever built a scraper that worked like a charm on your local machine only to watch it crumble in the cloud, you know the feeling.
Everything looks green on the dashboard. The requests are resolving. The logs say 200 OK. But three weeks later, a stakeholder points out that the data is garbage. The prices are wrong, the products are missing, and your "successful" pipeline has been feeding the business hallucinations.
The truth? Your code probably isn't the problem. Most scraping systems don't fail because of a logic error; they fail because they can't handle the "silent rot" of the web environment.
1. The "200 OK" Lie
Modern scraping stacks are actually quite robust at handling HTML parsing and retries. Those are solved problems. The real bottleneck is environmental drift.
Imagine a price monitor running across Europe. The selectors are fine. The code hasn’t changed. But because of the proxy's IP reputation or geo-location:
Market A sees VAT-inclusive prices.
Market B gets a "soft" redirect to a landing page.
Market C sees a "Product Unavailable" notice that looks like a valid empty state.
The system didn't crash. It failed operationally while technically succeeding.
2. Silent Failure: The Invisible Budget Killer
A hard crash is a gift, it tells you exactly where to fix it. A soft failure is a nightmare.
Websites have become experts at serving "ghost" pages: valid HTML that contains CAPTCHAs, limited search results, or localized content intended to mislead automated agents. From your scraper's perspective, it got a response. From a business perspective, you’re making decisions based on corrupted data.
The Lesson: If you aren't validating the integrity of the content, you aren't really scraping; you're just downloading noise.
3. Quality Over Quantity (The Proxy Trap)
There is a persistent myth that a larger proxy pool equals better reliability. In reality, massive, low-quality pools are often "polluted."
Aggressive Rotation: Can actually trigger anomaly detection by making your session behavior look erratic.
IP Reputation: A small set of "clean," stable residential IPs is infinitely more valuable than 100,000 blacklisted data center IPs.
This is where infrastructure providers like Evomi shift the needle. By treating proxies as stateful assets rather than disposable commodities, they ensure geographic consistency and session continuity. It’s the difference between a bot that looks like a bot and a bot that looks like a loyal customer.
4. Retries are a Double-Edged Sword
We love a good retry logic, but in production, it often just masks structural decay.
If a scraper hits a wall and you increase retries from 3 to 10, your "success rate" might go up, but your data freshness plummets. You’re effectively brute-forcing your way into accepting stale or throttled data.
In production, you need to distinguish between a "hiccup" (transient network error) and a "block" (reputation-based rejection). Treating them the same is just delaying the inevitable collapse.
5. Observability: More Than Just Uptime
A production scraper needs to answer more than "Did it run?" It needs to answer:
Did the average response size drop by 20%?
Are failures clustering around a specific provider or region?
Has the "Price" field suddenly become null in 5% of records?
Without deep observability, proxy issues don't show up as alerts, they show up as bad quarterly reports.
The Bottom Line
At scale, web scraping is no longer a coding challenge, it’s an infrastructure challenge.
It’s about managing reputation, matching human-like behavior, and choosing a "reliability layer" that can handle the heat of a production workload. If your data is drifting, stop looking at your scripts and start looking at your proxies.
Stop optimizing for volume. Start optimizing for trust.

Author
The Scraper
Engineer and Webscraping Specialist
About Author
The Scraper is a software engineer and web scraping specialist, focused on building production-grade data extraction systems. His work centers on large-scale crawling, anti-bot evasion, proxy infrastructure, and browser automation. He writes about real-world scraping failures, silent data corruption, and systems that operate at scale.

