The Rotation Fallacy: Why Brute-Force Proxying Breaks Production Scrapers


The Scraper
Proxy Fundamentals
In the world of web scraping, "rotate your IPs" has become the universal troubleshooting advice. Getting blocked? Rotate. Seeing CAPTCHAs? Rotate faster. Data looks weird? Rotate harder.
The assumption is that if you change your digital "face" often enough, you become invisible.
In reality, proxy rotation isn’t a strategy, it’s a tool. And when you use a hammer to perform surgery, you shouldn't be surprised when the patient doesn't make it.
1. The "Synthetic User" Footprint
Modern anti-bot systems have moved past simple IP counting. They don’t just look at who you are (your IP address); they look at how you behave across time.
If every single request to a target site comes from a different IP, a different TLS fingerprint, and a different ASN, you don’t look stealthy. You look synthetic. You are creating a digital footprint that no real human could ever produce.
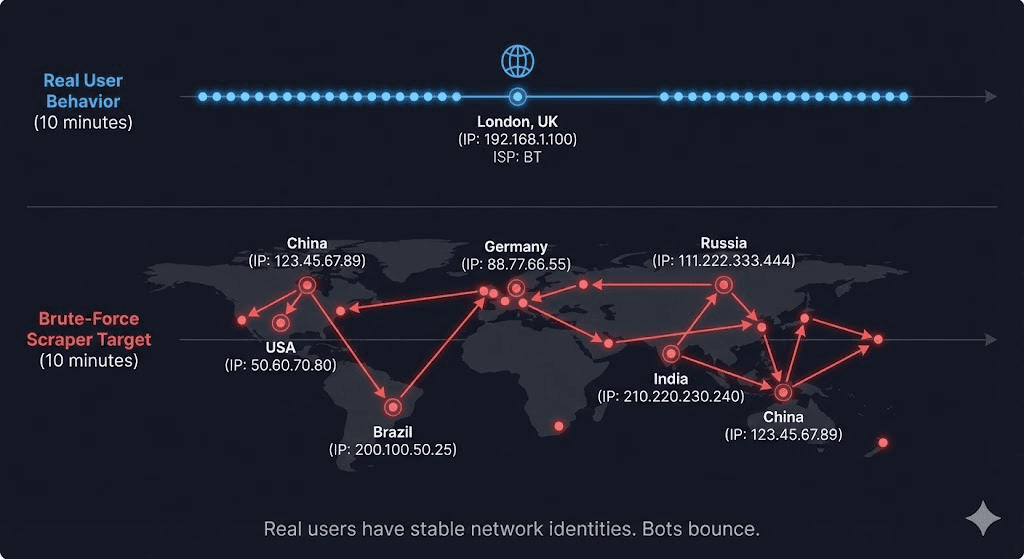
Visualizing the Problem
Imagine mapping the network requests of a real user versus a brute-force scraper over 10 minutes.
2. When Rotation Becomes a Red Flag (The Code View)
There are scenarios where aggressive rotation is effectively "suicide by infrastructure."
If you are scraping a site that requires a session, like a login, a shopping cart, or a multi-step search filter, rotating every request will break the continuity that the server expects.
The Wrong Way (Stateless Rotation on Stateful Target)
This Python snippet demonstrates a common mistake: trying to maintain a session while aggressively rotating the underlying network identity.
Python
In this scenario, rotation didn't help you avoid a block; it caused the block because the behavior was anomalous.
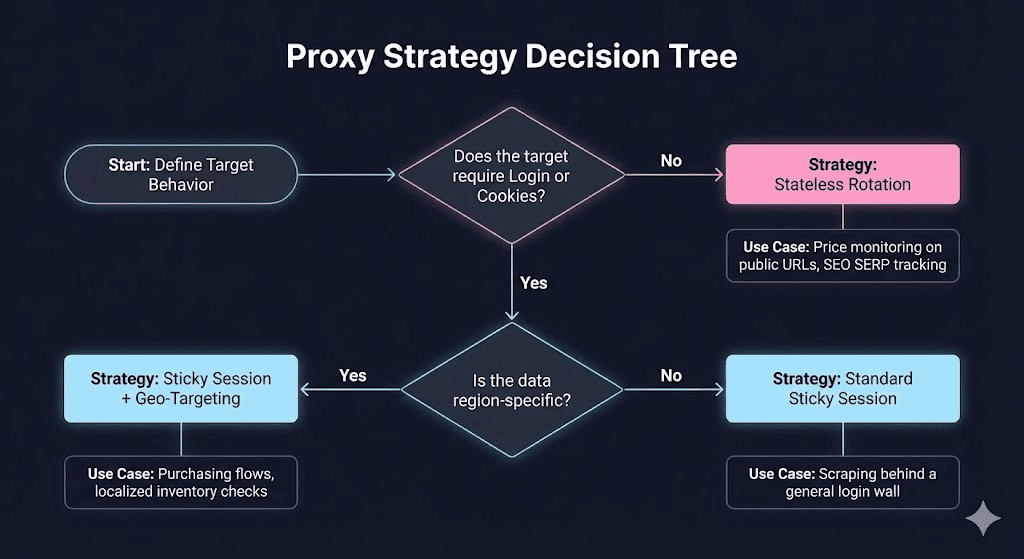
3. Strategy Shift: Deciding When to Rotate
The real question isn’t if you should rotate, but how the target expects you to stick around. You need to choose between Stateless High-Availability and Session-Aware Persistence.
Here is a decision matrix for choosing your approach:
The Tale of Two Scrapers
In session-aware scraping, IP consistency is your best friend. Here, the quality and stability of the IP matter significantly more than the raw size of the proxy pool.
Feature | Stateless Scraping | Session-Aware Scraping |
|---|---|---|
IP Strategy | High-frequency rotation (New IP per request) | Sticky Sessions (Keep IP for 10-30 mins) |
Goal | Maximize request volume / second | Maintain a stable identity |
Common Failure | Rate Limiting (429s) | Behavioral flagging / Session invalidation |
Ideal Proxy Type | Datacenter or high-churn Residential | Stable Residential or ISP (Static Resi) |
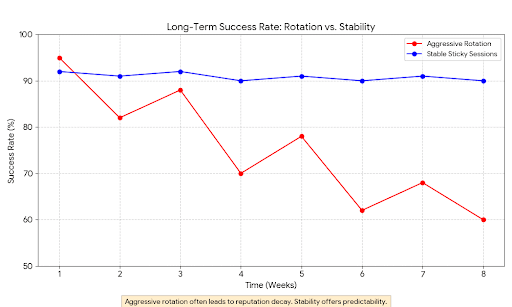
4. The Impact on Success Rates Over Time
Why do providers like Evomi emphasize "stateful assets" over massive, churning pools? Because stability pays off in the long run.
When you rely on aggressive rotation, your success rate often starts high but degrades quickly as your pool gets burned or your behavior gets flagged. When you use sticky, clean IPs aligned with user behavior, your success rate remains predictable.
The Takeaway
If your scraping strategy relies solely on rotation to stay alive, you aren't building a system, you're just gambling with your block rate.
The teams that win in production don't ask, "How often should we rotate?" They ask, "What behavior does this site actually expect?"
Stop treating proxies as disposable masks. Start treating them as the foundation of your scraper’s identity.
References & Further Reading
RFC 6265: HTTP State Management Mechanism (Cookies) - Understanding how servers track sessions.
OWASP Automated Threats to Web Applications - Specifically OAT-015 (Denial of Service) and OAT-007 (Credential Cracking), which often trigger rotation-based defenses.
Evomi Documentation on Sticky Sessions - Practical implementation of persistent IP sessions in production.
In the world of web scraping, "rotate your IPs" has become the universal troubleshooting advice. Getting blocked? Rotate. Seeing CAPTCHAs? Rotate faster. Data looks weird? Rotate harder.
The assumption is that if you change your digital "face" often enough, you become invisible.
In reality, proxy rotation isn’t a strategy, it’s a tool. And when you use a hammer to perform surgery, you shouldn't be surprised when the patient doesn't make it.
1. The "Synthetic User" Footprint
Modern anti-bot systems have moved past simple IP counting. They don’t just look at who you are (your IP address); they look at how you behave across time.
If every single request to a target site comes from a different IP, a different TLS fingerprint, and a different ASN, you don’t look stealthy. You look synthetic. You are creating a digital footprint that no real human could ever produce.
Visualizing the Problem
Imagine mapping the network requests of a real user versus a brute-force scraper over 10 minutes.
2. When Rotation Becomes a Red Flag (The Code View)
There are scenarios where aggressive rotation is effectively "suicide by infrastructure."
If you are scraping a site that requires a session, like a login, a shopping cart, or a multi-step search filter, rotating every request will break the continuity that the server expects.
The Wrong Way (Stateless Rotation on Stateful Target)
This Python snippet demonstrates a common mistake: trying to maintain a session while aggressively rotating the underlying network identity.
Python
In this scenario, rotation didn't help you avoid a block; it caused the block because the behavior was anomalous.
3. Strategy Shift: Deciding When to Rotate
The real question isn’t if you should rotate, but how the target expects you to stick around. You need to choose between Stateless High-Availability and Session-Aware Persistence.
Here is a decision matrix for choosing your approach:
The Tale of Two Scrapers
In session-aware scraping, IP consistency is your best friend. Here, the quality and stability of the IP matter significantly more than the raw size of the proxy pool.
Feature | Stateless Scraping | Session-Aware Scraping |
|---|---|---|
IP Strategy | High-frequency rotation (New IP per request) | Sticky Sessions (Keep IP for 10-30 mins) |
Goal | Maximize request volume / second | Maintain a stable identity |
Common Failure | Rate Limiting (429s) | Behavioral flagging / Session invalidation |
Ideal Proxy Type | Datacenter or high-churn Residential | Stable Residential or ISP (Static Resi) |
4. The Impact on Success Rates Over Time
Why do providers like Evomi emphasize "stateful assets" over massive, churning pools? Because stability pays off in the long run.
When you rely on aggressive rotation, your success rate often starts high but degrades quickly as your pool gets burned or your behavior gets flagged. When you use sticky, clean IPs aligned with user behavior, your success rate remains predictable.
The Takeaway
If your scraping strategy relies solely on rotation to stay alive, you aren't building a system, you're just gambling with your block rate.
The teams that win in production don't ask, "How often should we rotate?" They ask, "What behavior does this site actually expect?"
Stop treating proxies as disposable masks. Start treating them as the foundation of your scraper’s identity.
References & Further Reading
RFC 6265: HTTP State Management Mechanism (Cookies) - Understanding how servers track sessions.
OWASP Automated Threats to Web Applications - Specifically OAT-015 (Denial of Service) and OAT-007 (Credential Cracking), which often trigger rotation-based defenses.
Evomi Documentation on Sticky Sessions - Practical implementation of persistent IP sessions in production.
In the world of web scraping, "rotate your IPs" has become the universal troubleshooting advice. Getting blocked? Rotate. Seeing CAPTCHAs? Rotate faster. Data looks weird? Rotate harder.
The assumption is that if you change your digital "face" often enough, you become invisible.
In reality, proxy rotation isn’t a strategy, it’s a tool. And when you use a hammer to perform surgery, you shouldn't be surprised when the patient doesn't make it.
1. The "Synthetic User" Footprint
Modern anti-bot systems have moved past simple IP counting. They don’t just look at who you are (your IP address); they look at how you behave across time.
If every single request to a target site comes from a different IP, a different TLS fingerprint, and a different ASN, you don’t look stealthy. You look synthetic. You are creating a digital footprint that no real human could ever produce.
Visualizing the Problem
Imagine mapping the network requests of a real user versus a brute-force scraper over 10 minutes.
2. When Rotation Becomes a Red Flag (The Code View)
There are scenarios where aggressive rotation is effectively "suicide by infrastructure."
If you are scraping a site that requires a session, like a login, a shopping cart, or a multi-step search filter, rotating every request will break the continuity that the server expects.
The Wrong Way (Stateless Rotation on Stateful Target)
This Python snippet demonstrates a common mistake: trying to maintain a session while aggressively rotating the underlying network identity.
Python
In this scenario, rotation didn't help you avoid a block; it caused the block because the behavior was anomalous.
3. Strategy Shift: Deciding When to Rotate
The real question isn’t if you should rotate, but how the target expects you to stick around. You need to choose between Stateless High-Availability and Session-Aware Persistence.
Here is a decision matrix for choosing your approach:
The Tale of Two Scrapers
In session-aware scraping, IP consistency is your best friend. Here, the quality and stability of the IP matter significantly more than the raw size of the proxy pool.
Feature | Stateless Scraping | Session-Aware Scraping |
|---|---|---|
IP Strategy | High-frequency rotation (New IP per request) | Sticky Sessions (Keep IP for 10-30 mins) |
Goal | Maximize request volume / second | Maintain a stable identity |
Common Failure | Rate Limiting (429s) | Behavioral flagging / Session invalidation |
Ideal Proxy Type | Datacenter or high-churn Residential | Stable Residential or ISP (Static Resi) |
4. The Impact on Success Rates Over Time
Why do providers like Evomi emphasize "stateful assets" over massive, churning pools? Because stability pays off in the long run.
When you rely on aggressive rotation, your success rate often starts high but degrades quickly as your pool gets burned or your behavior gets flagged. When you use sticky, clean IPs aligned with user behavior, your success rate remains predictable.
The Takeaway
If your scraping strategy relies solely on rotation to stay alive, you aren't building a system, you're just gambling with your block rate.
The teams that win in production don't ask, "How often should we rotate?" They ask, "What behavior does this site actually expect?"
Stop treating proxies as disposable masks. Start treating them as the foundation of your scraper’s identity.
References & Further Reading
RFC 6265: HTTP State Management Mechanism (Cookies) - Understanding how servers track sessions.
OWASP Automated Threats to Web Applications - Specifically OAT-015 (Denial of Service) and OAT-007 (Credential Cracking), which often trigger rotation-based defenses.
Evomi Documentation on Sticky Sessions - Practical implementation of persistent IP sessions in production.

Author
The Scraper
Engineer and Webscraping Specialist
About Author
The Scraper is a software engineer and web scraping specialist, focused on building production-grade data extraction systems. His work centers on large-scale crawling, anti-bot evasion, proxy infrastructure, and browser automation. He writes about real-world scraping failures, silent data corruption, and systems that operate at scale.


