Google vs. SerpAPI: The Legal Battle Over Who Owns the Search Result


The Scraper
Scraping Techniques
For decades, web scraping has occupied a legal gray area, the "Wild West" of the digital economy. Search engines scrape the web, SEO tools scrape the search engines, and AI models scrape everything in between. It is a massive ecosystem built entirely on automated data collection.
However, that ecosystem is currently facing a defining legal challenge. Google’s lawsuit against SerpAPI, a service that provides structured access to search engine results, is more than a corporate dispute. It is a fundamental interrogation of the internet's architecture: Who controls access to data that is publicly visible but technically guarded?
The Business of "Structured" Search
SerpAPI doesn't just "visit" Google; it translates the visual web into machine-readable data. By bypassing the manual labor of parsing HTML, it provides developers with clean, structured JSON feeds of organic results, ads, and local listings.
This data is the lifeblood of the modern web. From SEO platforms and market research tools to e-commerce intelligence, dozens of industries rely on this "middleman" layer to understand how the world searches. While SerpAPI is far from the only player in this space, Google’s decision to target them specifically marks a shift from passive defense to active litigation.
The Shift in Legal Strategy
Historically, cases like hiQ Labs v. LinkedIn suggested that scraping publicly accessible data was generally protected. But Google is pivoting. Their argument isn't just about the data; it’s about the process.
Google alleges that SerpAPI:
Deploys massive volumes of automated queries that strain infrastructure.
Systematically bypasses anti-bot protections.
Repackages and resells proprietary search layouts for commercial gain.
By invoking DMCA Section 1201 (the anti-circumvention provision), Google is moving the goalposts. They are arguing that even if the data is public, the act of "breaking the lock" (bypassing CAPTCHAs or IP blocks) to get it is illegal. If the courts agree, it sets a massive precedent: scraping becomes a liability the moment you bypass a technical barrier.
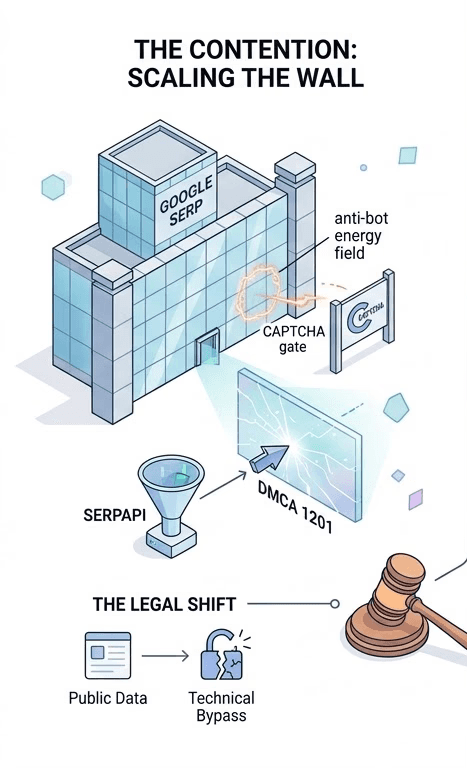
Why the Stakes Are So High
For Google, this is about protecting their "secret sauce." Search results reveal their ranking algorithms, their advertising revenue streams, and their competitive edge. For the scraping industry, it’s an existential threat. A Google victory could empower every major platform to gate-keep public information behind technical barriers, effectively ending the era of "open" public data.
The Future of Data Infrastructure
The industry won't vanish, but it will be forced to mature. We are moving away from "clever scripts" and toward sophisticated, sustainable infrastructure. Success in this new landscape depends on responsible request patterns and transparent proxy networks.
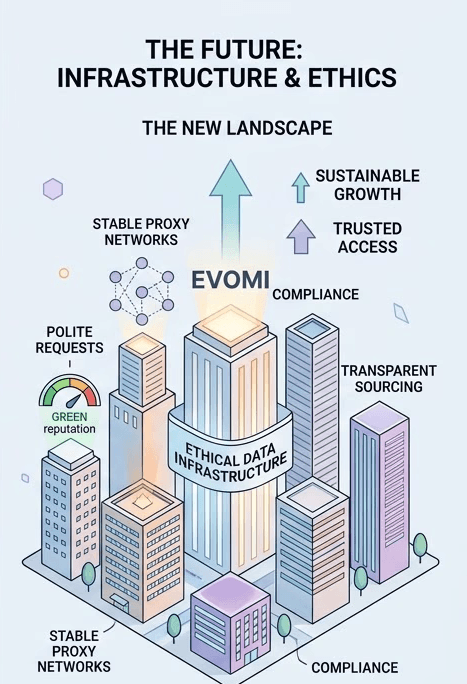
Providers like Evomi are already shifting the focus toward ethical sourcing and network stability, recognizing that the future of scraping relies as much on compliance as it does on code. As the legal environment tightens, having a partner that understands the nuance of IP reputation and "polite" scraping becomes a competitive necessity rather than a luxury.
Ultimately, the Google vs. SerpAPI case reflects the central tension of the modern web: Platforms want total control, while businesses demand open access. The court's decision won't just impact two companies; it will define how the next generation of data-driven AI and SEO tools are built.

Author
The Scraper
Engineer and Webscraping Specialist
About Author
The Scraper is a software engineer and web scraping specialist, focused on building production-grade data extraction systems. His work centers on large-scale crawling, anti-bot evasion, proxy infrastructure, and browser automation. He writes about real-world scraping failures, silent data corruption, and systems that operate at scale.


