

Collect structured data at scale - without headless overhead.
High-speed data extraction built for developers and teams.
99.9 % Uptime
<200ms Latency
150 Regions
Trusted by institutions & developers worldwide


API DEMO
See how teams automate structured data collection
Eliminate the complexity of managing proxies and headless browsers. Just send a URL to our API, and we handle the rendering, parsing, and delivery to return clean, ready-to-use JSON in seconds.
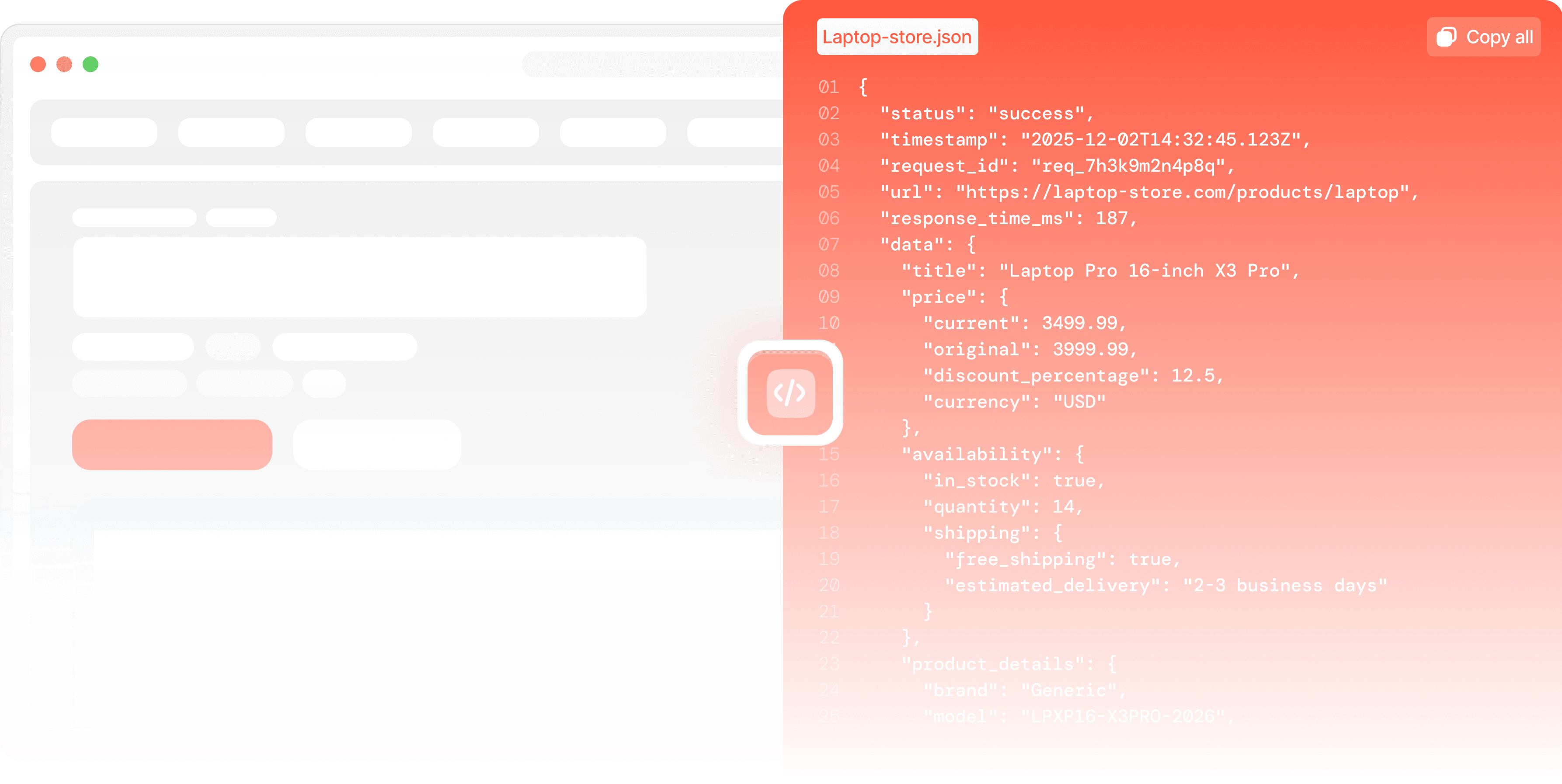
Input
Send any URL through our API
Processing
Our distributed network handle extraction
Output
Get clean, structured JSON data instantly
PRICING
Transparent Pricing for Every Scale
Flexible subscriptions with no hidden fees. Pay only for successful requests and scale your concurrency instantly as your data needs grow.

FEATURES
Extract Faster Without Complex Setup
Maintain reliable access without wrestling IP rotation or CAPTCHA handling. Our infrastructure manages fingerprinting, automatic retries, and residential proxy rotation, allowing you to focus on analyzing data rather than maintaining scrapers.



JS Rendering
Full browser execution for dynamic content.
Headless Browser
Chrome-based rendering infrastructure.
Screenshot Capture
Full-page visual snapshots on demand.
Geotargeting
195+ countries, down to city-level precision.
Auto Rotation
Reliable Access
Fingerprint
UA Rotator
Headers
Proxy Management
Analytics

INTEGRATIONS
Connects With Your Stack
Evomi’s Scraping API works seamlessly with almost every provider






FAQs
Frequently Asked Questions
Our mission is to provide reliable, scalable, and ethically sourced proxy solutions for businesses of all sizes. We are committed to transparency and innovation.

Start Scraping Smarter
Build Your First Workflow in Minutes
30 Day money-back guarantee
Instant Setup