Your Proxy Bill Is a Lie: The Hidden Economics of Scraping at Scale


The Scraper
Proxy Fundamentals
Every proxy vendor puts a number on the front page. $0.49/GB. $1.20/GB. $3/GB. You compare those numbers, pick the lowest one that fits your use case, and call it a budget.
That number is not your proxy cost. It's a fraction of your proxy cost. The rest is hiding in places your billing dashboard doesn't show.
What You're Actually Paying For
When a scraping engineer says "we spend $X/month on proxies," they're usually quoting the line item on the vendor invoice. But proxies don't operate in isolation. They sit at the top of a cost stack, and every block, every failed request, every corrupt data point downstream has a dollar value attached to it.
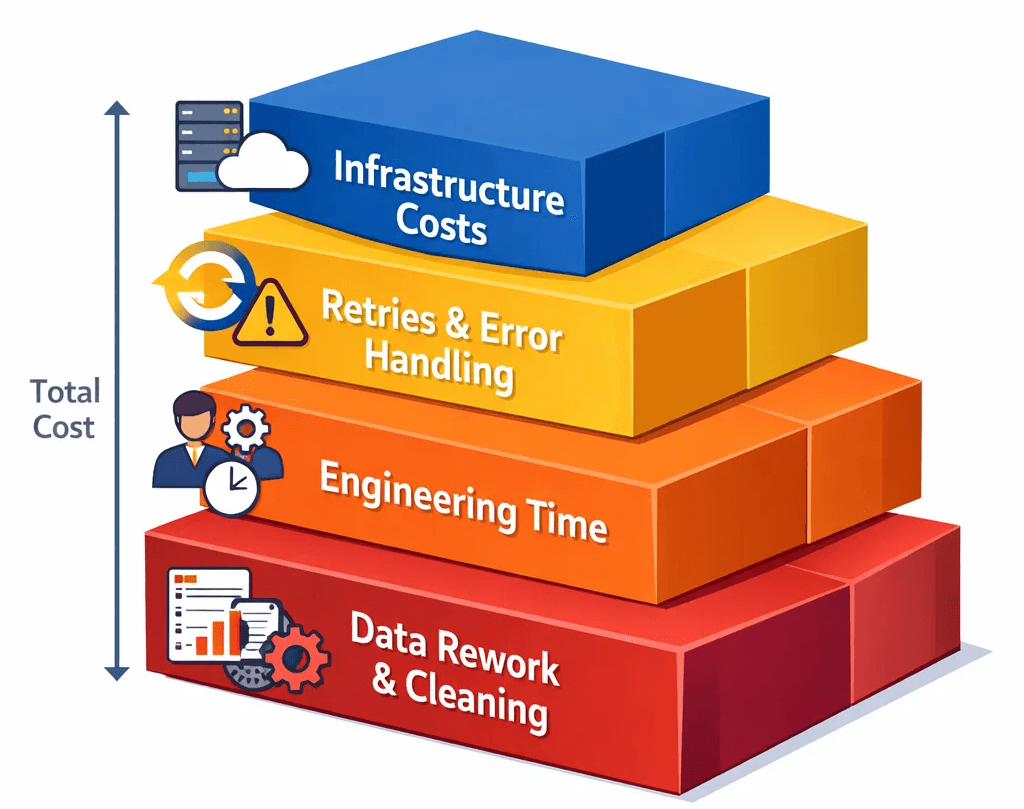
The true cost of a scraping request has four components:
Infrastructure cost: what the proxy vendor charges for bandwidth consumed.
Retry cost: every blocked or failed request that has to be re-issued. If your success rate on a protected target is 60%, you're paying for 1.67 requests per successful result. That multiplier compounds every operation in your pipeline.
Engineering cost: the hours your team spends debugging proxy-related failures, rotating providers, tuning retry logic, and investigating soft blocks. This is the most invisible cost and often the largest one.
Downstream data cost: when a blocked request returns a poisoned page (a bot-detection page, a CAPTCHA, a blank result), and your pipeline processes it as valid data, you get silent corruption. Deduplication, schema repair, and manual audit are expensive. Decisions made on bad data are more expensive still.
The proxy bill tells you about line item one. It says nothing about two, three, or four.
The $0.49 vs. $1.20 Calculation
Here's the math that most procurement decisions miss.
Suppose you're scraping a moderately protected e-commerce target, Cloudflare Business tier, basic behavioral analysis. Your pipeline needs 100,000 successful product pages per day.
Option A: $0.49/GB residential proxy
Success rate on this target: 55%
Requests needed: 181,818 (to get 100,000 clean results)
Average page size: 400KB
Daily bandwidth: ~72GB
Daily proxy cost: $35.28
Retry overhead: 81,818 extra requests, each consuming compute, queue time, and retry logic
Engineering incidents per month from provider reliability issues: ~3 (avg. 1.5 hours each)
Option B: $1.20/GB premium residential proxy
Success rate on this target: 92%
Requests needed: 108,695
Daily bandwidth: ~43GB
Daily proxy cost: $51.60
Retry overhead: 8,695 extra requests
Engineering incidents per month: ~0.5
Option A looks $16/day cheaper. It isn't. The retry volume alone increases compute costs. The engineering time alone, at a conservative $80/hour fully burdened, adds $360/month. The data quality delta compounds further.
The cheap proxy is almost never cheap. It's just cheap to invoice.
The Metrics That Actually Matter
If you're evaluating a proxy provider on $/GB, you're optimizing the wrong variable. The metrics that determine real cost:
Success rate by target tier. Not aggregate success rate, that's padded by easy targets. What's the success rate on your hardest tier? Cloudflare Enterprise? DataDome-protected checkout flows? If the vendor can't give you this number, that tells you something.
Block rate vs. soft-block rate. A hard block (4xx, challenge page) at least fails fast and retries cleanly. A soft block, a page that returns 200 with bot-detection content, is the silent killer. Your pipeline consumes bandwidth, compute, and storage processing a result that was never valid. Providers with clean IP pools have dramatically lower soft-block rates.
IP freshness and pool turnover. Burned IPs that stay in rotation inflate your bandwidth consumption without producing successful results. High-quality providers actively retire flagged IPs. Cheap providers don't.
Geographic precision. If your target requires city-level geo-matching, for localized pricing, regional inventory, or currency display, a provider that routes you through the wrong metro costs you in data accuracy, not just request failures.
The Fraud Score Problem
Here's the variable that's hardest to quantify but most important: every IP in a proxy pool has an implicit fraud score on the major bot-detection networks. IPs that have been used for credential stuffing, ad fraud, or aggressive scraping by previous users accumulate reputational debt. That debt is yours when you rent the IP.
Low-cost providers with large pools often have weak vetting standards. You're not buying a clean IP, you're inheriting the history of whoever used it before you. On a well-instrumented target like a major retail or travel site, a high fraud-score IP will fail before it even sends a request.
Consent-based, ethically sourced pools have a structural advantage here. IPs that entered the pool through legitimate opt-in programs haven't been used for malicious traffic. Their fraud scores are clean. That cleanliness is what you're paying for when you pay a premium.
Where Evomi's Pricing Model Fits
Evomi's residential proxies start at $0.49/GB, competitive on the raw bandwidth metric, but the important variable is what's behind that number. Ethically sourced IPs, active pool hygiene, and a success-rate profile that holds up on protected targets. The $0.49 entry point is for use cases where you don't need maximum penetration. For targets that require it, Evomi's premium residential pool provides a higher-quality subset at a tiered price, the right tool for the right tier, rather than a one-size-fits-all upsell.
The point isn't to optimize the invoice line. It's to optimize the fully-loaded cost per clean result. You can test either tier with a completely free trial before committing budget.
The New Cost Model
The engineers running efficient scraping operations at scale don't evaluate proxy providers on $/GB. They evaluate on:
Cost per successful result (accounting for success rate and retries)
Engineering hours per month attributable to proxy-related failures
Data quality incident rate from soft blocks reaching downstream storage
Time-to-block on high-value targets (how long before a session is flagged)
Build a simple model. Take your target tier, estimate the success rate difference between providers, multiply by your volume, and convert retries to compute cost and engineering hours. The number will surprise you.
The proxy bill is what you pay. The proxy cost is what you spend. They are not the same number.
Stop optimizing the bill.

Author
The Scraper
Engineer and Webscraping Specialist
About Author
The Scraper is a software engineer and web scraping specialist, focused on building production-grade data extraction systems. His work centers on large-scale crawling, anti-bot evasion, proxy infrastructure, and browser automation. He writes about real-world scraping failures, silent data corruption, and systems that operate at scale.


