The Death of the Selector: Why AI Extraction Is Eating CSS Queries


The Scraper
Proxy Fundamentals
The Death of the Selector: Why AI Extraction Is Eating CSS Queries
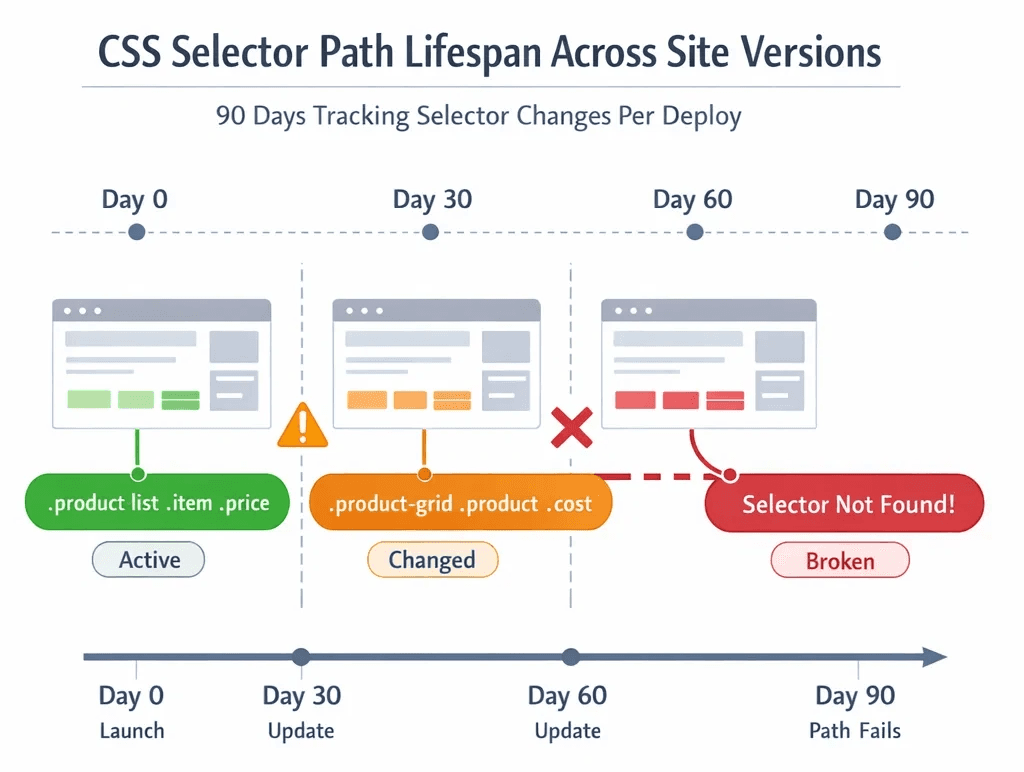
The selector div.product-tile > span.price-value worked great. Until Tuesday, when the site pushed a redesign and it became div[data-testid="product-card"] .pricing__amount. You updated it. Two weeks later, they A/B tested a new checkout flow. It broke again.
This is the lifecycle of every scraper built on CSS and XPath. A fragile contract between your code and a UI you don't control, renegotiated every time a frontend developer merges a branch.
The Old World: Selectors Are Syntactic, Not Semantic
Traditional scrapers don't understand "price." They understand nth-child(2) > .value. That gap matters more than most engineers admit.
CSS selectors and XPath have been the default extraction mechanism since the early days of BeautifulSoup and Scrapy. For a static page with a stable DOM, they're fast, deterministic, and easy to audit. The problem is that almost no page is stable anymore.
Modern web apps are component-driven, server-rendered on the fly, and split-tested constantly. Tailwind, shadcn/ui, CSS Modules, class names are hashed, generated, or semantically meaningless. A class like .price-display becomes .text-xl.font-semibold.text-green-600 in the next Figma handoff. XPath breaks even faster: the DOM tree restructures with every framework migration, every responsive redesign, every personalization variant served to your scraper's session.
The maintenance math compounds quietly. A selector that works on desktop fails on the mobile layout. A rule that works for anonymous sessions returns different content for authenticated ones. You end up with a growing matrix of brittle conditional logic, each path held together with monitors you hope never fire.
And those monitors don't catch the worst failure mode.
The silent failure, where a selector still matches but now returns the wrong element, is the one that kills data quality downstream. Your pipeline keeps running. The numbers keep flowing. Someone flags it three weeks later when the anomaly crosses a threshold. By then, you have three weeks of poisoned data.
Selector-based scrapers are optimized for the happy path. The web is not a happy path.
The Shift: Intent-Based Extraction
What AI-Native Tools Actually Do
Firecrawl, Kadoa, and AgentQL take a fundamentally different approach. Instead of asking "what is the CSS path to this element?", they ask "find me the price on this page." The extraction target is semantic, not syntactic.
Under the hood, these tools feed the rendered HTML (and in some cases a structured DOM representation) to an LLM, typically GPT-4o, Claude 3.5 Sonnet, or a fine-tuned extraction model, and ask it to locate and return the fields you care about. The model understands what "product name", "current price", and "review count" mean in context. It doesn't need to be told where they live.
AgentQL expresses this with a query language that reads like intent:
query = """ { products[] { name price availability rating } } ""
The system resolves which DOM nodes correspond to those fields at runtime. If the site redesigns tomorrow, the query still works. You're not maintaining selectors. You're maintaining intent.
Firecrawl takes a slightly different path, it converts pages to clean Markdown or structured JSON before passing them to your extraction logic, making LLM parsing cheaper and more reliable. Kadoa goes further and automates the full ETL pipeline across heterogeneous sources, abstracting selectors out of the picture entirely.
The Real Trade-Offs
This shift comes with costs practitioners need to understand clearly before committing to the stack.
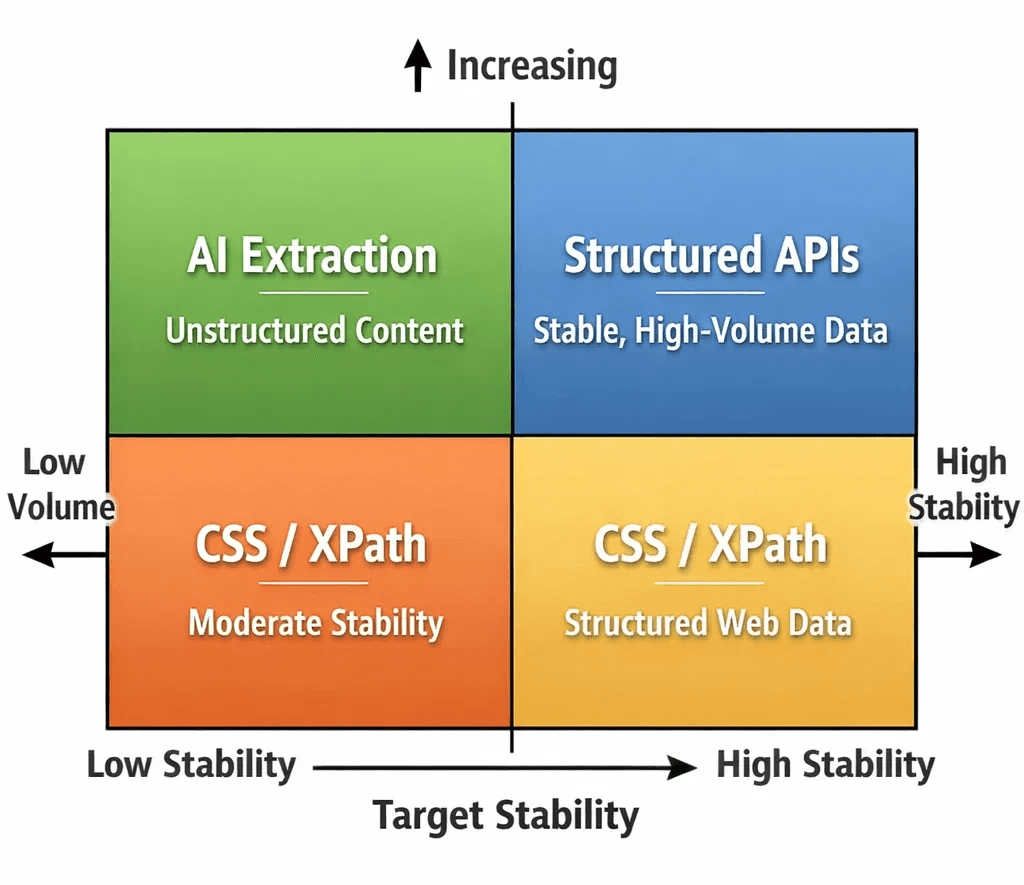
Latency. An LLM inference pass on a rendered page takes 1–4 seconds, depending on context length and model tier. A CSS selector runs in microseconds. For scraping at scale, millions of pages per day, this gap is not abstract. It reshapes your concurrency model, your infrastructure spend, and your pipeline SLAs.
Cost. Firecrawl and Kadoa price per page. AgentQL uses token-based billing. For high-volume commodity scraping, job listings, product catalogs at massive scale, the unit economics don't yet favor AI extraction. For precision extraction of high-value targets (executive contact data, competitive pricing, financial disclosures), they often do.
Accuracy. LLMs hallucinate. Semantic extraction can misidentify fields on unusual layouts, dense tables, or ambiguously labeled content. A traditional selector fails in binary, obvious ways: it returns nothing, or the wrong node. An AI extractor can return something plausible but incorrect, and that's harder to catch. Schema validation and range checks downstream are not optional in this stack.
Where the Math Flips
The maintenance burden comparison changes quickly for specific use cases.
If you're scraping a target that redesigns quarterly and you're burning engineering hours each cycle, AI extraction is cheaper over six months even at $10 per 1,000 pages. If you're building a product that ingests structured data from hundreds of heterogeneous sources, Kadoa's core use case, maintaining individual selector sets per domain isn't viable at any cost.
The sweet spot right now: medium-volume, high-value extraction across diverse or unstable targets. Not the firehose commodity scrape. The surgical intelligence layer.
The Part the Extraction Vendors Don't Say Out Loud
AI extraction solves the parsing problem. It does not solve the access problem.
Firecrawl, Kadoa, AgentQL, they still have to GET the page. A Cloudflare-protected target doesn't care how sophisticated your LLM extraction layer is. The challenge of appearing as a legitimate browser, from a clean residential IP, with consistent TLS and behavioral fingerprints, that's upstream of everything. An LLM can't interpret a 403. It can't extract data from a CAPTCHA wall.
This is where your infrastructure layer becomes the binding constraint. AI extractors work best when they receive a clean, fully rendered HTML payload, a page delivered without blocks, soft denials, or honeypot content. Getting there requires residential IPs with low fraud scores and a browser execution environment that passes fingerprint checks at the TLS layer and above.
Pairing your AI extraction stack with Evomi's residential proxies provides the access layer those tools depend on, 9.5M+ ethically sourced IPs across 195+ countries, with the fraud score profile that high-trust targets require. For browser-based extraction workflows, Evomi's Scraping Browser handles rendering, session management, and anti-bot bypass, so the page your LLM receives is actually the page you wanted, not the bot-detection variant. You can test either with a completely free trial.
The New Stack
The scraping architecture is separating into two distinct layers that used to be conflated in a single Scrapy spider or Playwright script:
Access layer: residential/mobile proxy rotation, browser fingerprint management, behavioral mimicry, anti-bot bypass. Infrastructure work.
Extraction layer: parsing, structuring, and normalizing data from retrieved pages. Increasingly an ML problem.
If your current architecture treats these as one problem, 2026 is a good year to rethink the boundary.
The stack that survives layout changes:
Managed browser or headless browser with residential proxy rotation → handles access
AI extraction layer (
firecrawl,agentql, Kadoa) → handles parsingSchema validation + range guards → catches LLM extraction errors
Structured storage (BigQuery, Postgres) → downstream consumers
The selector isn't gone from this picture entirely, AgentQL still resolves to DOM nodes, Firecrawl still parses HTML. But you no longer maintain those mappings. The model does.
The Bottom Line
CSS selectors aren't dying because they're bad. They're dying because the web was never a stable API and we've spent fifteen years pretending it was. AI extraction is the honest response to that reality.
The engineers who will fall behind are the ones waiting for AI extraction to become "production-ready." It already is, for the right targets, at the right scale, with the right infrastructure underneath it.
The Death of the Selector: Why AI Extraction Is Eating CSS Queries
The selector div.product-tile > span.price-value worked great. Until Tuesday, when the site pushed a redesign and it became div[data-testid="product-card"] .pricing__amount. You updated it. Two weeks later, they A/B tested a new checkout flow. It broke again.
This is the lifecycle of every scraper built on CSS and XPath. A fragile contract between your code and a UI you don't control, renegotiated every time a frontend developer merges a branch.
The Old World: Selectors Are Syntactic, Not Semantic
Traditional scrapers don't understand "price." They understand nth-child(2) > .value. That gap matters more than most engineers admit.
CSS selectors and XPath have been the default extraction mechanism since the early days of BeautifulSoup and Scrapy. For a static page with a stable DOM, they're fast, deterministic, and easy to audit. The problem is that almost no page is stable anymore.
Modern web apps are component-driven, server-rendered on the fly, and split-tested constantly. Tailwind, shadcn/ui, CSS Modules, class names are hashed, generated, or semantically meaningless. A class like .price-display becomes .text-xl.font-semibold.text-green-600 in the next Figma handoff. XPath breaks even faster: the DOM tree restructures with every framework migration, every responsive redesign, every personalization variant served to your scraper's session.
The maintenance math compounds quietly. A selector that works on desktop fails on the mobile layout. A rule that works for anonymous sessions returns different content for authenticated ones. You end up with a growing matrix of brittle conditional logic, each path held together with monitors you hope never fire.
And those monitors don't catch the worst failure mode.
The silent failure, where a selector still matches but now returns the wrong element, is the one that kills data quality downstream. Your pipeline keeps running. The numbers keep flowing. Someone flags it three weeks later when the anomaly crosses a threshold. By then, you have three weeks of poisoned data.
Selector-based scrapers are optimized for the happy path. The web is not a happy path.
The Shift: Intent-Based Extraction
What AI-Native Tools Actually Do
Firecrawl, Kadoa, and AgentQL take a fundamentally different approach. Instead of asking "what is the CSS path to this element?", they ask "find me the price on this page." The extraction target is semantic, not syntactic.
Under the hood, these tools feed the rendered HTML (and in some cases a structured DOM representation) to an LLM, typically GPT-4o, Claude 3.5 Sonnet, or a fine-tuned extraction model, and ask it to locate and return the fields you care about. The model understands what "product name", "current price", and "review count" mean in context. It doesn't need to be told where they live.
AgentQL expresses this with a query language that reads like intent:
query = """ { products[] { name price availability rating } } ""
The system resolves which DOM nodes correspond to those fields at runtime. If the site redesigns tomorrow, the query still works. You're not maintaining selectors. You're maintaining intent.
Firecrawl takes a slightly different path, it converts pages to clean Markdown or structured JSON before passing them to your extraction logic, making LLM parsing cheaper and more reliable. Kadoa goes further and automates the full ETL pipeline across heterogeneous sources, abstracting selectors out of the picture entirely.
The Real Trade-Offs
This shift comes with costs practitioners need to understand clearly before committing to the stack.
Latency. An LLM inference pass on a rendered page takes 1–4 seconds, depending on context length and model tier. A CSS selector runs in microseconds. For scraping at scale, millions of pages per day, this gap is not abstract. It reshapes your concurrency model, your infrastructure spend, and your pipeline SLAs.
Cost. Firecrawl and Kadoa price per page. AgentQL uses token-based billing. For high-volume commodity scraping, job listings, product catalogs at massive scale, the unit economics don't yet favor AI extraction. For precision extraction of high-value targets (executive contact data, competitive pricing, financial disclosures), they often do.
Accuracy. LLMs hallucinate. Semantic extraction can misidentify fields on unusual layouts, dense tables, or ambiguously labeled content. A traditional selector fails in binary, obvious ways: it returns nothing, or the wrong node. An AI extractor can return something plausible but incorrect, and that's harder to catch. Schema validation and range checks downstream are not optional in this stack.
Where the Math Flips
The maintenance burden comparison changes quickly for specific use cases.
If you're scraping a target that redesigns quarterly and you're burning engineering hours each cycle, AI extraction is cheaper over six months even at $10 per 1,000 pages. If you're building a product that ingests structured data from hundreds of heterogeneous sources, Kadoa's core use case, maintaining individual selector sets per domain isn't viable at any cost.
The sweet spot right now: medium-volume, high-value extraction across diverse or unstable targets. Not the firehose commodity scrape. The surgical intelligence layer.
The Part the Extraction Vendors Don't Say Out Loud
AI extraction solves the parsing problem. It does not solve the access problem.
Firecrawl, Kadoa, AgentQL, they still have to GET the page. A Cloudflare-protected target doesn't care how sophisticated your LLM extraction layer is. The challenge of appearing as a legitimate browser, from a clean residential IP, with consistent TLS and behavioral fingerprints, that's upstream of everything. An LLM can't interpret a 403. It can't extract data from a CAPTCHA wall.
This is where your infrastructure layer becomes the binding constraint. AI extractors work best when they receive a clean, fully rendered HTML payload, a page delivered without blocks, soft denials, or honeypot content. Getting there requires residential IPs with low fraud scores and a browser execution environment that passes fingerprint checks at the TLS layer and above.
Pairing your AI extraction stack with Evomi's residential proxies provides the access layer those tools depend on, 9.5M+ ethically sourced IPs across 195+ countries, with the fraud score profile that high-trust targets require. For browser-based extraction workflows, Evomi's Scraping Browser handles rendering, session management, and anti-bot bypass, so the page your LLM receives is actually the page you wanted, not the bot-detection variant. You can test either with a completely free trial.
The New Stack
The scraping architecture is separating into two distinct layers that used to be conflated in a single Scrapy spider or Playwright script:
Access layer: residential/mobile proxy rotation, browser fingerprint management, behavioral mimicry, anti-bot bypass. Infrastructure work.
Extraction layer: parsing, structuring, and normalizing data from retrieved pages. Increasingly an ML problem.
If your current architecture treats these as one problem, 2026 is a good year to rethink the boundary.
The stack that survives layout changes:
Managed browser or headless browser with residential proxy rotation → handles access
AI extraction layer (
firecrawl,agentql, Kadoa) → handles parsingSchema validation + range guards → catches LLM extraction errors
Structured storage (BigQuery, Postgres) → downstream consumers
The selector isn't gone from this picture entirely, AgentQL still resolves to DOM nodes, Firecrawl still parses HTML. But you no longer maintain those mappings. The model does.
The Bottom Line
CSS selectors aren't dying because they're bad. They're dying because the web was never a stable API and we've spent fifteen years pretending it was. AI extraction is the honest response to that reality.
The engineers who will fall behind are the ones waiting for AI extraction to become "production-ready." It already is, for the right targets, at the right scale, with the right infrastructure underneath it.
The Death of the Selector: Why AI Extraction Is Eating CSS Queries
The selector div.product-tile > span.price-value worked great. Until Tuesday, when the site pushed a redesign and it became div[data-testid="product-card"] .pricing__amount. You updated it. Two weeks later, they A/B tested a new checkout flow. It broke again.
This is the lifecycle of every scraper built on CSS and XPath. A fragile contract between your code and a UI you don't control, renegotiated every time a frontend developer merges a branch.
The Old World: Selectors Are Syntactic, Not Semantic
Traditional scrapers don't understand "price." They understand nth-child(2) > .value. That gap matters more than most engineers admit.
CSS selectors and XPath have been the default extraction mechanism since the early days of BeautifulSoup and Scrapy. For a static page with a stable DOM, they're fast, deterministic, and easy to audit. The problem is that almost no page is stable anymore.
Modern web apps are component-driven, server-rendered on the fly, and split-tested constantly. Tailwind, shadcn/ui, CSS Modules, class names are hashed, generated, or semantically meaningless. A class like .price-display becomes .text-xl.font-semibold.text-green-600 in the next Figma handoff. XPath breaks even faster: the DOM tree restructures with every framework migration, every responsive redesign, every personalization variant served to your scraper's session.
The maintenance math compounds quietly. A selector that works on desktop fails on the mobile layout. A rule that works for anonymous sessions returns different content for authenticated ones. You end up with a growing matrix of brittle conditional logic, each path held together with monitors you hope never fire.
And those monitors don't catch the worst failure mode.
The silent failure, where a selector still matches but now returns the wrong element, is the one that kills data quality downstream. Your pipeline keeps running. The numbers keep flowing. Someone flags it three weeks later when the anomaly crosses a threshold. By then, you have three weeks of poisoned data.
Selector-based scrapers are optimized for the happy path. The web is not a happy path.
The Shift: Intent-Based Extraction
What AI-Native Tools Actually Do
Firecrawl, Kadoa, and AgentQL take a fundamentally different approach. Instead of asking "what is the CSS path to this element?", they ask "find me the price on this page." The extraction target is semantic, not syntactic.
Under the hood, these tools feed the rendered HTML (and in some cases a structured DOM representation) to an LLM, typically GPT-4o, Claude 3.5 Sonnet, or a fine-tuned extraction model, and ask it to locate and return the fields you care about. The model understands what "product name", "current price", and "review count" mean in context. It doesn't need to be told where they live.
AgentQL expresses this with a query language that reads like intent:
query = """ { products[] { name price availability rating } } ""
The system resolves which DOM nodes correspond to those fields at runtime. If the site redesigns tomorrow, the query still works. You're not maintaining selectors. You're maintaining intent.
Firecrawl takes a slightly different path, it converts pages to clean Markdown or structured JSON before passing them to your extraction logic, making LLM parsing cheaper and more reliable. Kadoa goes further and automates the full ETL pipeline across heterogeneous sources, abstracting selectors out of the picture entirely.
The Real Trade-Offs
This shift comes with costs practitioners need to understand clearly before committing to the stack.
Latency. An LLM inference pass on a rendered page takes 1–4 seconds, depending on context length and model tier. A CSS selector runs in microseconds. For scraping at scale, millions of pages per day, this gap is not abstract. It reshapes your concurrency model, your infrastructure spend, and your pipeline SLAs.
Cost. Firecrawl and Kadoa price per page. AgentQL uses token-based billing. For high-volume commodity scraping, job listings, product catalogs at massive scale, the unit economics don't yet favor AI extraction. For precision extraction of high-value targets (executive contact data, competitive pricing, financial disclosures), they often do.
Accuracy. LLMs hallucinate. Semantic extraction can misidentify fields on unusual layouts, dense tables, or ambiguously labeled content. A traditional selector fails in binary, obvious ways: it returns nothing, or the wrong node. An AI extractor can return something plausible but incorrect, and that's harder to catch. Schema validation and range checks downstream are not optional in this stack.
Where the Math Flips
The maintenance burden comparison changes quickly for specific use cases.
If you're scraping a target that redesigns quarterly and you're burning engineering hours each cycle, AI extraction is cheaper over six months even at $10 per 1,000 pages. If you're building a product that ingests structured data from hundreds of heterogeneous sources, Kadoa's core use case, maintaining individual selector sets per domain isn't viable at any cost.
The sweet spot right now: medium-volume, high-value extraction across diverse or unstable targets. Not the firehose commodity scrape. The surgical intelligence layer.
The Part the Extraction Vendors Don't Say Out Loud
AI extraction solves the parsing problem. It does not solve the access problem.
Firecrawl, Kadoa, AgentQL, they still have to GET the page. A Cloudflare-protected target doesn't care how sophisticated your LLM extraction layer is. The challenge of appearing as a legitimate browser, from a clean residential IP, with consistent TLS and behavioral fingerprints, that's upstream of everything. An LLM can't interpret a 403. It can't extract data from a CAPTCHA wall.
This is where your infrastructure layer becomes the binding constraint. AI extractors work best when they receive a clean, fully rendered HTML payload, a page delivered without blocks, soft denials, or honeypot content. Getting there requires residential IPs with low fraud scores and a browser execution environment that passes fingerprint checks at the TLS layer and above.
Pairing your AI extraction stack with Evomi's residential proxies provides the access layer those tools depend on, 9.5M+ ethically sourced IPs across 195+ countries, with the fraud score profile that high-trust targets require. For browser-based extraction workflows, Evomi's Scraping Browser handles rendering, session management, and anti-bot bypass, so the page your LLM receives is actually the page you wanted, not the bot-detection variant. You can test either with a completely free trial.
The New Stack
The scraping architecture is separating into two distinct layers that used to be conflated in a single Scrapy spider or Playwright script:
Access layer: residential/mobile proxy rotation, browser fingerprint management, behavioral mimicry, anti-bot bypass. Infrastructure work.
Extraction layer: parsing, structuring, and normalizing data from retrieved pages. Increasingly an ML problem.
If your current architecture treats these as one problem, 2026 is a good year to rethink the boundary.
The stack that survives layout changes:
Managed browser or headless browser with residential proxy rotation → handles access
AI extraction layer (
firecrawl,agentql, Kadoa) → handles parsingSchema validation + range guards → catches LLM extraction errors
Structured storage (BigQuery, Postgres) → downstream consumers
The selector isn't gone from this picture entirely, AgentQL still resolves to DOM nodes, Firecrawl still parses HTML. But you no longer maintain those mappings. The model does.
The Bottom Line
CSS selectors aren't dying because they're bad. They're dying because the web was never a stable API and we've spent fifteen years pretending it was. AI extraction is the honest response to that reality.
The engineers who will fall behind are the ones waiting for AI extraction to become "production-ready." It already is, for the right targets, at the right scale, with the right infrastructure underneath it.

Author
The Scraper
Engineer and Webscraping Specialist
About Author
The Scraper is a software engineer and web scraping specialist, focused on building production-grade data extraction systems. His work centers on large-scale crawling, anti-bot evasion, proxy infrastructure, and browser automation. He writes about real-world scraping failures, silent data corruption, and systems that operate at scale.


